[Paper Brief]: MapReduce: Simplified Data Processing on Large Clusters (2004)
What is it?
MapReduce is an abstract design that facilitate building computational jobs but hides the complicated details of parallelization, fault-tolerance, data distribution and load balancing.It is inspired by the map and reduce functions present in many other functional languages.
Why do we need it?
Before the advent of MapReduce, Google has implemented enormous number of computions that support for processing of raw data to compute various devired data. For the most part, the computations are conceptually straightforward, yet the hardest obstacles come from finished with large input data in reasonable time by distributed computations across hundreds or thousands commodity PCs.The main goal is therefore to bring an interface that blurs the complexity of distributed system ( parallelization, fault-tolerance, data distribution, and load balancing ) for entry level engineers. Another benefit that comes along is easy-scale in horizontal manner.
What is the model?
As mentioned before, It's based on 2 functions in functional languages. Map and Reduce functions are written by users with specific purpose and in predefined form. $Map$ : takes input as a pair key/value for identifying and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function. $Reduce$ : accepts an intermediate key and a set of values for that key. It merges together these values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user’s reduce function via an iterator. This allows us to handle lists of values that are too large to fit in memory.
map = function(k1,v1) -> list(k2,v2)
reduce = function(k2, list(v2)) -> list(v2)
Pseudo Code example of counting the number of occurrences of each word in a large collection of documents:
map (String key, String value):
// value: document contents
for each word w in value:
Emit Intermediate (w, "1");
reduce (String key, Iterator values) :
// key: a word
// values: a list of counts int result = 0;
for each v in values:
result += parseInt (v);
Emit (As String (result));
How is it implemented?
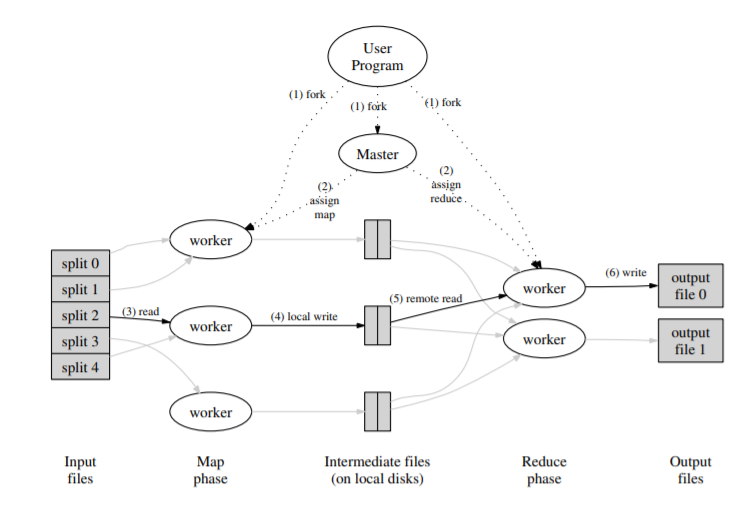 The detailed diagram from original paper.
The detailed diagram from original paper.
The above figure shows the overall flow of MapReduce. The following sequence of actions occurs when MapReduce is called ( the numbered labels in Figure 1 correspond to the numbers in the list below ) :
- Firstly, input data is split into $M$ pieces of 16MB-64MB/piece ( configured via an optional parameter ) by the MapReduce library in user program. It then starts up many copies of the program on a cluster of machines.
- One of the copies of the program is special - the master. The rest are workers that are assigned work and controlled by the master. There are $M$ map task and $R$ reduce tasks. The master tends to pick idle workers and assign each one a map or reduce task at a time.
- A worker who is assigned a map task reads the contents of the corresponding input split. Iit parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in the memory.
- Periodically, the buffered pairs are written to local disk, partitioned into $R$ regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
- When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used.
- The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user's Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
- When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the $MapReduce$ call in the user program returns back to the user code.
How about distributed aspects?
State
$idle$ $ \rightarrow$ $in-progress$ $\rightarrow$ $completed$
Fault tolerance
- Worker failure: A woker is marked as failed if it doesnt response heartbeats to master in a certain amount of time.
Then the MapReduce re-execute the work done by unreachable worker machines, and continued to make forward progress. All following tasks is re-executed:
- Completed map tasks.
- In-progress map tasks.
- In-progress reduce tasks.
- Master failure: In case of master failure, a new copy can be started from the last checkpoint state. In order to achieve it, master must write periodic checkpoint itself.
Locality
Instead of fetching or moving data to computational server, MapReduce delivery computations to data server. Most of the time, data is read locally and it consumes no network bandwith. For this, GFS do partition data among clusters automatically.
"Straggler"
A worker is named as "Straggeler", If its completion time exceed normal period.
It spawns backup copies tasks when the primary task is close to completion. The task is marked as completed whenever either the primary or the backup execution completes. At the end, this works like a charm on reducing the completion time significantly about 44%.
What did we learn from MapReduce ?
- Restricting the programming model makes it easy to parallelize and distribute computations and to make such computations fault-tolerant.
- Network bandwidth is a scarce resource. A number of optimizations in our system are therefore targeted at reducing the amount of data sent across the network: the locality optimization allows us to read data from local disks, and writing a single copy of the intermediate data to local disk saves network bandwidth. And nowaday it's not a big deal any more.
- Redundant execution can be used to reduce the impact of slow machines, and to handle machine failures and data loss.